List view
Quick Start
Quick Start
User Guide
User Guide
Policies & GuardRails
Policies & GuardRails
Witness Anywhere: Remote Device Security
Witness Anywhere: Remote Device Security
Witness Attack
Witness Attack
Administrator Guide
Administrator Guide
Harmful Response Prevention GuardRail (Beta)
Harmful Response Prevention is WitnessAI’s response analysis and control Guardrail. The purpose of this Guardrail is to analyze the responses back from AI models to user prompts, and then detect, and optionally prevent these responses from being sent to the user. These harmful responses are evaluated in three broad categories; harm to self, harm to others, and illegal activity. When this Guardrail detects these activities, it provides the option to Allow, Warn, or Block the response from the AI model with a customizable message.
Use Cases
Harm to self or others
Block or warn Users about dangerous AI responses, such as the possibility that AI Model responses may contain unqualified or inaccurate medical or financial information.
Illegal activity
Block or warn Users about dangerous AI responses, particularly common activities that may expose individuals or the Organization to legal risks.
Using Harmful Response Prevention Step-by-Step
This section covers details on the Harmful Response Prevention GuardRail, and how to add it to a Policy. Refer to the Policy Creation page for how to create Policies.
Add a Harmful Response Prevention GuardRail
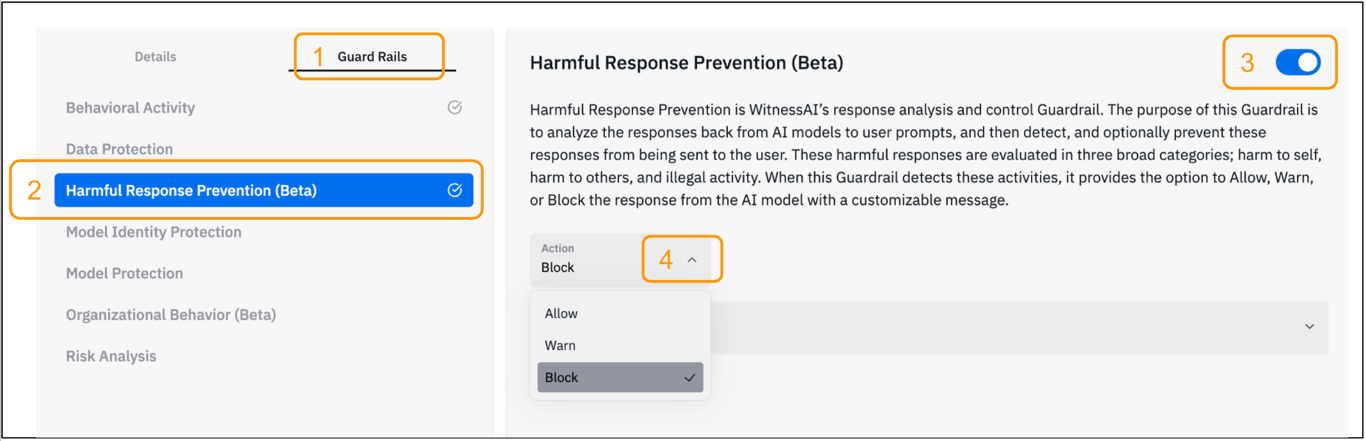
After creating a Policy
- Click the Guard Rails tab in the policy editor.
- Select the Harmful Response Prevention GuardRail from the available options.
- Click the slide button to enable the GuardRail.
- Click the drop-down for the ‘Action’ field and choose Allow, Warn, or Block.
- Optionally click the drop-down for the ‘Message’ field and choose the message to show the user when a Harmful Response is detected. A custom message can be added if desired.
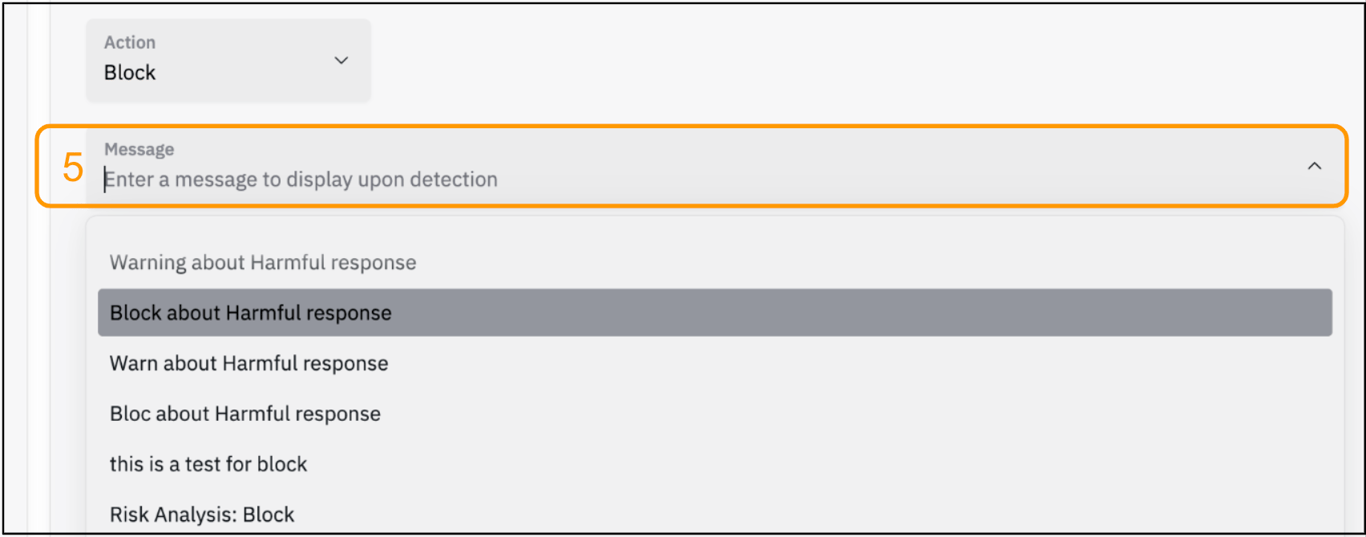
- Save the configuration.
 Made with Bullet
Made with Bullet